Interim Futility for Negative Binomial Endpoints
Sebastian Weber
2026-07-06
Source:vignettes/articles/negbin_interim_futility.Rmd
negbin_interim_futility.RmdIntroduction
Clinical trials with recurrent event endpoints — such as asthma exacerbations — typically require large sample sizes and long follow-up. These features make early interim analyses (IAs) for futility attractive: stopping a trial that is unlikely to succeed saves resources and avoids exposing patients to ineffective treatments.
However, a futility IA at a low information fraction (e.g. 30%) has limited statistical power. The data collected so far carry substantial uncertainty, making it difficult to distinguish a truly futile scenario from random noise. This is where historical borrowing via a Meta-Analytic-Predictive (MAP) prior can help: by incorporating external evidence on the control rate and overdispersion, the MAP prior effectively supplements the interim data, increasing the information fraction available at the IA and enabling more precise futility decisions.
This article develops the idea in four steps:
- Baseline: Operating characteristics (OC) of a fixed-sample design without an IA.
- Unblinded futility IA without borrowing: Introduce a futility stop at 30% information fraction using non-informative priors. Quantify the power loss under the alternative.
- Unblinded futility IA with MAP prior: Derive a MAP prior from four historical phase III trials. Show the effective sample size (ESS) and the information fraction gained.
- Interim decision-making: Conditional power and predictive power (probability of success) at a hypothesized interim state.
- Design-level power: Numerical integration over the full trial to quantify the expected power loss from the futility IA under the alternative.
Throughout, the final confirmatory analysis is purely frequentist — the MAP prior is used only for interim projections.
Negative binomial setup
In clinical trials with count data, where more than one event can happen for a patient — such as asthma exacerbations — the negative binomial distribution is often used. One of several parametrizations uses a mean rate and a dispersion parameter. It extends the Poisson distribution — which assumes that all patients with the same covariate values share a single event rate — by allowing the event rate to vary between patients (the larger the dispersion parameter, the more the event rate varies between patients). Differences in follow-up due to administrative censoring can be reflected using a log-follow-up offset, i.e. the expected number of events for a patient is their event rate times their follow-up time.
We work on the log mean rate scale under the standard normal approximation to the MLE (see Appendix for the full parametrization). The treatment effect is the log-rate ratio .
## Assumed true parameters for design planning
lambda_ctrl <- 1.8 # placebo rate (events/patient-year)
kappa_true <- 1.9 # overdispersion (phi)
## Effective average follow-up per patient (years). Rather than a full
## year for everyone, we allow for ~15% dropout with, on average, half
## the intended follow-up (cf. Holzhauer et al., 2018):
## 1 * 0.85 + 0.5 * 0.15 = 0.925 patient-years.
followup <- 1 * 0.85 + 0.5 * 0.15
log_exposure <- log(followup)
## NB family object for OC calculations (fixed kappa)
nb_family <- negative.binomial(theta = 1 / kappa_true)
## Per-patient sampling SD on the log-rate scale
## sigma = sqrt((1 + kappa * lambda * t) / (lambda * t))
sigma_fn <- function(lambda, kappa, t) {
sqrt((1 + kappa * lambda * t) / (lambda * t))
}
sigma_ctrl <- round(sigma_fn(lambda_ctrl, kappa_true, followup), 2)
sigma_treat <- sigma_ctrl # same rate assumed under H0
cat(sprintf("Per-patient sigma (log-rate scale): %.3f\n", sigma_ctrl))## Per-patient sigma (log-rate scale): 1.580Fixed-sample design (no interim)
We first evaluate the operating characteristics of a conventional 2-arm trial without an interim analysis.
## Priors — non-informative for both arms (no borrowing)
uninf_ctrl <- mixnorm(c(1, log(lambda_ctrl), 10), sigma = sigma_ctrl)
uninf_treat <- mixnorm(c(1, log(lambda_ctrl), 10), sigma = sigma_treat)
## Sample sizes
n_treat <- 225
n_ctrl <- 225
## Decision: P(delta < 0 | data) > 0.975 (one-sided test)
success_crit <- decision2S(0.975, 0, lower.tail = TRUE)
## OC function
oc_fixed <- oc2S(uninf_treat, uninf_ctrl,
n1 = n_treat, n2 = n_ctrl,
decision = success_crit,
family = nb_family,
offset1 = log_exposure, offset2 = log_exposure
)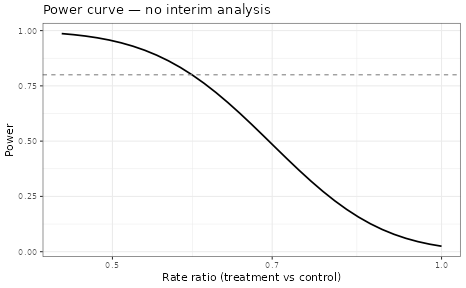
Power curve — fixed-sample design (no IA)
Futility IA at 30% information fraction (no borrowing)
We now add a futility stop at 30% of the planned information. With no historical borrowing, the IA relies entirely on the accrued trial data. This would be a very early stop with rather imprecise estimates compared to a more common IA look at 50%.
As a simplifying assumption we treat the interim analysis as if it were based on 30% of the patients with complete follow-up. In practice the same information would come from more patients, many of them with only partial follow-up at the time of the interim look; their data can still be used through the use of an offset in the regression. This distinction is not merely cosmetic: for a recurrent-event endpoint the information is event-driven, so a given amount of total follow-up ( expected follow-up per patient) is worth slightly more when it comes from many patients observed for a short time than from fewer patients each observed to completion. The calculation here is thus somewhat simplfying the actual situation.
The information fraction is defined as the ratio of the Fisher information for the treatment effect (log rate ratio) at the interim relative to the final analysis. Under a negative binomial model with log link, the per-patient Fisher information for in arm is , and the information for the treatment effect from and patients is We compute the interim sample sizes required for 30% of at the planned final sample size, evaluated under the design alternative :
| Quantity | Value |
|---|---|
| Design alternative log(RR) | -0.43 |
| Per-patient Fisher info (treatment) | 0.3541 |
| Per-patient Fisher info (control) | 0.3999 |
| Information at final (n/arm) | 42.26 (n = 225) |
| Information target at IA (30%) | 12.68 |
| Patients at IA (treatment / control) | 68 / 68 |
| Patients remaining (treatment / control) | 157 / 157 |
The futility rule is based on predictive power (probability of success): given the interim posterior, what is the probability that the final analysis — using all planned patients — will declare success?
If the PoS falls below a futility threshold (e.g. 10%), we stop:
## Futility threshold for PoS
post_futility_thresh <- 0.10Operating characteristics of the IA design
To evaluate the operating characteristics of the design with
the futility IA, we use numerical integration via
oc2S_interim(). This function avoids noisy Monte Carlo
estimation via Gauss-Hermite quadrature over the distribution of
possible interim outcomes (see Appendix:
Integration approach for details).
The interim decision rule continues the trial whenever the probability of success exceeds the futility threshold:
## IA continuation rule: continue if PoS > threshold.
## The predictive power (PoS) is computed from the interim projection
## posteriors: the (uninformative) treatment posterior and the control
## posterior. This exact same rule is reused below for the MAP design —
## only the control interim prior (prior2_ia) changes, not the rule.
## Note: we use the fixed-sigma path of pos2S (no family argument)
## for performance. This is valid because sigma is approximately
## constant over the posterior range at the interim.
ia_rule_pos <- function(post1_ia, post2_ia, post1_ia_info, post2_ia_info) {
pos2S(post1_ia, post2_ia,
n1 = n_treat - n_treat_ia, n2 = n_ctrl - n_ctrl_ia,
decision = success_crit,
sigma1 = sigma_ctrl, sigma2 = sigma_ctrl)(post1_ia_info, post2_ia_info) > post_futility_thresh
}
## OC function with futility IA (no borrowing).
## prior1/prior2 are uninformative (used for the final analysis boundary);
oc_ia_uninf <- oc2S_interim(
prior1 = uninf_treat, prior2 = uninf_ctrl,
n1 = n_treat, n2 = n_ctrl,
n1_ia = n_treat_ia, n2_ia = n_ctrl_ia,
decision = success_crit,
ia_rule = ia_rule_pos,
prior1_ia = uninf_treat, prior2_ia = uninf_ctrl,
family = nb_family,
offset1 = log_exposure, offset2 = log_exposure,
Ngrid_ia = 31L
)
## Evaluate at null and the design alternative (pos2S rule is expensive)
log_rr_grid <- c(`No benefit` = 0, `Design alt` = log_rr_design)
power_ia_uninf_df <- oc_ia_uninf(
theta1 = log_mu_ctrl + log_rr_grid,
theta2 = rep(log_mu_ctrl, length(log_rr_grid))
)
power_ia_uninf_df$log_rr <- log_rr_grid
## Compare with fixed-design power at same grid points
power_fixed_grid <- oc_fixed(log_mu_ctrl + log_rr_grid,
rep(log_mu_ctrl, length(log_rr_grid)))| Scenario | Rate ratio | Fixed design | IA (no borrow) | Power loss | Futility stop |
|---|---|---|---|---|---|
| No benefit | 1.00 | 0.025 | 0.022 | 0.002 | 0.579 |
| Design alt | 0.65 | 0.800 | 0.774 | 0.026 | 0.066 |
At 30% information fraction with non-informative priors, the futility IA already behaves quite well: it stops a clearly ineffective drug (rate ratio = 1) with high probability — well above one half — while costing only about one and a half percentage points of power under the design alternative. This is more effective than one might expect from such an early look. What the non-informative design cannot do is separate “stop for the right reason” from “stop because the 30%-information estimate happened to look bad”; the interim data alone carry limited information, so the decision is comparatively noisy. Historical borrowing (next section) sharpens exactly this.
MAP prior from historical phase III trials
Historical data
We use placebo-arm data from the phase III asthma trials in the
asthma data set (Table 1 of Holzhauer, Wang & Schmidli,
2018):
asthma_ph3 <- subset(asthma, phase == "phase III")| study | d | n | log_mu_hat | se_log_mu_hat | kappa_hat | |
|---|---|---|---|---|---|---|
| 3 | Study_3 | 0.62 | 191 | 0.56 | 0.11 | 1.43 |
| 4 | Study_4 | 1.00 | 244 | 0.59 | 0.10 | 1.97 |
| 5 | Study_5 | 1.00 | 232 | 0.75 | 0.13 | 3.38 |
| 8 | Study_8 | 0.46 | 66 | 0.75 | 0.16 | 0.67 |
MAP prior for the control log-rate
The historical trials have different exposure (follow-up) durations
.
Here the summaries provided in the asthma data set are
already on the yearly log-rate scale (log events per
patient-year, back-calculated from the raw counts and exposures), so
log_mu_hat estimates
directly and no offset is needed:
map_mcmc <- gMAP(
cbind(log_mu_hat, se_log_mu_hat) ~ 1 | study,
## NOTE: the historical inputs are already log-rates (per patient-year),
## so no exposure offset is used here. If instead the inputs were
## log-mean *counts* log(mu) = log(lambda * d) for exposure d, we would
## add `offset = log(d)` to recover the log-rate log(lambda). Whether an
## offset is needed therefore depends on how the historical data are
## reported.
data = asthma_ph3,
family = gaussian,
tau.dist = "HalfNormal",
tau.prior = sigma_ctrl / 4,
beta.prior = 2
)## Assuming default prior location for beta: 0
print(map_mcmc)## Generalized Meta Analytic Predictive Prior Analysis
##
## Call: gMAP(formula = cbind(log_mu_hat, se_log_mu_hat) ~ 1 | study,
## family = gaussian, data = asthma_ph3, tau.dist = "HalfNormal",
## tau.prior = sigma_ctrl/4, beta.prior = 2)
##
## Exchangeability tau strata: 1
## Prediction tau stratum : 1
## Maximal Rhat : 1
##
## Between-trial heterogeneity of tau prediction stratum
## mean median sd q2.5 q50 q97.5
## tau[1] 0.119 0.0893 0.109 0.00349 0.0893 0.409
##
## MAP Prior MCMC sample
## mean median sd q2.5 q50 q97.5
## theta_resp_pred 0.649 0.644 0.191 0.281 0.644 1.08
map_rate <- automixfit(map_mcmc)
sigma(map_rate) <- sigma_ctrl
pl <- plot(map_mcmc)
## The gMAP model works on the log-rate scale, so the estimates are
## spaced logarithmically. We keep that geometry but label the ticks
## with the natural event rate (events/patient-year) for readability.
## Because plot.gMAP uses coord_flip(), the estimate lives on the y
## aesthetic, so we override scale_y_continuous().
rate_breaks <- c(1.25, 1.5, 1.75, 2.0, 2.5, 3.0)
print(pl$forest_model +
ggplot2::scale_y_continuous(
name = "Control event rate [events/patient-year]",
breaks = log(rate_breaks),
labels = rate_breaks))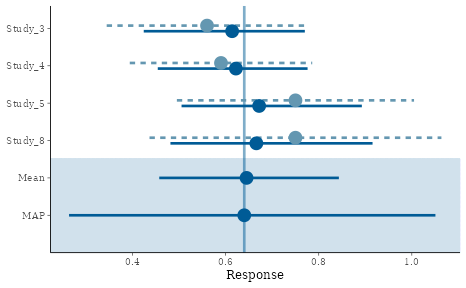
Forest plot of MAP model for control event rate
Effective sample size and information fraction gain
The ESS tells us how many patients the MAP prior is worth. It adds precision to the control arm only, so we fold it into the treatment-effect information defined above as extra control patients. The information fraction at the IA then uses the same ratio, now with :
ess_map <- round(ess(map_rate, sigma = sigma_ctrl))
## Effect information I(delta) at IA without borrowing
info_ia_no_borrow <- 1 / (1 / (n_treat_ia * Ip_treat) +
1 / (n_ctrl_ia * Ip_ctrl))
info_frac_no_borrow <- info_ia_no_borrow / info_final
## Effect information I(delta) at IA with MAP prior:
## ESS adds patient-equivalents to the CONTROL arm only.
info_ia_with_map <- 1 / (1 / (n_treat_ia * Ip_treat) +
1 / ((n_ctrl_ia + ess_map) * Ip_ctrl))
info_frac_with_map <- info_ia_with_map / info_final| Quantity | Value |
|---|---|
| MAP prior ESS | 163 patients |
| Info fraction at IA (no borrowing) | 30.2% |
| Info fraction at IA (with MAP prior) | 45.2% |
| Info fraction gained | +15.0 pp |
The MAP prior substantially increases the effective information fraction at the IA, which we would expect to make futility decisions more reliable.
Power with futility IA and MAP prior
## Same PoS futility rule as before (ia_rule_pos): continue if
## PoS > threshold. The interim projection now uses the MAP-informed
## control posterior (post2_ia_info) via prior2_ia = map_rate below;
## the continuation rule itself is unchanged. The pos2S boundary uses
## the uninformative posteriors, consistent with an uninformative
## final analysis.
## OC function with futility IA and MAP prior
## prior1/prior2 are uninformative (used for the final analysis boundary).
## prior1_ia is the uninformative treatment prior and prior2_ia is
## the MAP prior; both are used only for the interim decision.
oc_ia_map <- oc2S_interim(
prior1 = uninf_treat, prior2 = uninf_ctrl,
n1 = n_treat, n2 = n_ctrl,
n1_ia = n_treat_ia, n2_ia = n_ctrl_ia,
decision = success_crit,
ia_rule = ia_rule_pos,
prior1_ia = uninf_treat, prior2_ia = map_rate,
family = nb_family,
offset1 = log_exposure, offset2 = log_exposure,
Ngrid_ia = 31L
)
## Evaluate at two scenarios: no benefit (rate ratio = 1) and the
## design alternative. The pos2S-based rule is expensive, so we keep
## the grid small.
scenarios <- c(`No benefit` = 0, `Design alt` = log_rr_design)
theta1_eval <- log_mu_ctrl + scenarios
theta2_eval <- rep(log_mu_ctrl, length(scenarios))
map_grid <- oc_ia_map(theta1 = theta1_eval, theta2 = theta2_eval)
uninf_grid <- oc_ia_uninf(theta1 = theta1_eval, theta2 = theta2_eval)
fixed_power <- oc_fixed(theta1_eval, theta2_eval)| Scenario | Rate ratio | Power (no IA) | Power (no borrow) | Power (MAP) | Stop (no borrow) | Stop (MAP) |
|---|---|---|---|---|---|---|
| No benefit | 1.00 | 0.025 | 0.022 | 0.022 | 0.579 | 0.548 |
| Design alt | 0.65 | 0.800 | 0.774 | 0.790 | 0.066 | 0.030 |
The table compares the two designs at a common PoS futility threshold of 10%. Under the design alternative the futility IA costs about 1.6 percentage points of power without borrowing (80.0% → 78.4%); with the MAP prior the loss shrinks to about 1.0 percentage points (80.0% → 79.1%), and the chance of an erroneous futility stop under the alternative falls (roughly 4.6% → 2.9%). Under no treatment benefit (rate ratio = 1), however, the picture at this shared threshold is mixed: the non-informative design actually stops more often (about 63%) than the MAP design (about 57%). This is not a contradiction — at a common PoS threshold the two rules are simply not equally aggressive, so reading the null-stopping probabilities side by side compares apples to oranges.
Calibrating the futility threshold to a fixed power loss
Comparing the two designs at a shared futility threshold mixes two effects: the different threshold behaviour of the two analyses in terms of operating charachersitics and the different information they carry. An alternative, as poroposed by Gallo, Mao & Shih (2014), fixes one (Frequentist) operating characteristic for both methods and reads off the others. A futility rule can be expressed equivalently on several one-to-one scales — a test statistic, the observed effect estimate, conditional power, or predictive power — so the choice of scale is a matter of convenience once we agree on the operating characteristics we care about. Here we calibrate each method to the same power loss of 2% under the design alternative and then compare the futility stopping probability under the null.
A fast, equivalent futility scale. Evaluating the PoS at every quadrature node is expensive because each evaluation solves a small predictive-power (double) integral. Since the futility scales are one-to-one for a fixed design, we can instead use the interim posterior assurance for a positive treatment effect — the posterior probability that the treatment is better than control, , a monotone function of the interim posterior mean difference. This is far cheaper to compute (no inner predictive integral) yet traces the same power-loss / stopping-probability trade-off as the PoS rule. Importantly, the borrowing is fully retained: the control arm’s interim posterior is still formed from the MAP prior, so the assurance rule uses exactly the same MAP-informed control estimate — it only changes the scale on which the threshold is expressed, not the information used.
A deliberate asymmetry. Note that this uses the MAP prior only for the interim decision making. The final confirmatory analysis remains purely frequentist and never sees this prior. The interim decision analysis and the final analysis are therefore intentionally different: borrowing is a design/monitoring tool here, not part of the primary inference.
## Fast, equivalent futility scale: continue iff the interim posterior
## assurance P(delta < 0) exceeds a threshold gamma. This is a monotone
## re-scaling of the PoS rule (Gallo, Mao & Shih, 2014) but avoids the
## inner predictive integral, so the threshold search is ~25x faster.
## The MAP prior still enters via the control interim posterior
## (prior2_ia = map_rate below).
assurance_rule <- function(gamma) {
function(post1_ia, post2_ia, post1_ia_info, post2_ia_info) {
pmixdiff(post1_ia_info, post2_ia_info, 0) > gamma
}
}
make_oc_assurance <- function(gamma, prior2_ia, Ngrid_ia = 31L) {
oc2S_interim(
prior1 = uninf_treat, prior2 = uninf_ctrl,
n1 = n_treat, n2 = n_ctrl,
n1_ia = n_treat_ia, n2_ia = n_ctrl_ia,
decision = success_crit,
ia_rule = assurance_rule(gamma),
prior1_ia = uninf_treat, prior2_ia = prior2_ia,
family = nb_family,
offset1 = log_exposure, offset2 = log_exposure,
Ngrid_ia = Ngrid_ia
)
}The threshold that comes closest to a 2% power loss is found once
with uniroot. Because it depends only on the fixed design
inputs, we determine it in the (non-evaluated) block below and hard-code
the resulting values; they only change if the design inputs change.
## One-off calibration (not evaluated on render). Solves for the
## assurance threshold giving a 2% power loss under the design
## alternative, separately for each method.
## Design inputs these thresholds depend on:
## lambda_ctrl = 1.8, kappa_true = 1.9, followup = 0.925,
## n_treat = n_ctrl = 225, n_ia = 68/arm, log_rr_design = log(0.65),
## MAP prior = map_rate (asthma phase III, no offset),
## uninf_treat = N(0, 10), success_crit = P(delta<0) > 0.975.
target_power_loss <- 0.02
theta1_alt <- log_mu_ctrl + log_rr_design
theta2_alt <- log_mu_ctrl
power_alt_fixed <- oc_fixed(theta1_alt, theta2_alt)
## Two-stage search for speed. The interim OC is integrated by
## Gauss-Hermite quadrature, whose cost grows with Ngrid_ia. We first
## locate the threshold on a cheap coarse grid (Ngrid_ia = 11) over the
## full range, then refine on the accurate grid (Ngrid_ia = 31) seeded
## from a narrow bracket around the coarse solution. The bracket
## auto-extends (extendInt = "upX", as the power loss increases with
## gamma) so the refinement stays robust even though the coarse and
## accurate grids can disagree by more than the initial half-width.
solve_gamma <- function(prior2_ia) {
gfun <- function(gamma, Ngrid_ia) {
p <- make_oc_assurance(gamma, prior2_ia, Ngrid_ia)(theta1_alt, theta2_alt)["power"]
(power_alt_fixed - as.numeric(p)) - target_power_loss
}
## Stage 1: coarse, wide bracket.
g_coarse <- uniroot(gfun, interval = c(0.05, 0.90), tol = 1e-3,
Ngrid_ia = 11L)$root
## Stage 2: accurate grid, narrow self-extending bracket around it.
uniroot(gfun, interval = c(g_coarse - 0.01, g_coarse + 0.01),
extendInt = "upX", tol = 1e-3, Ngrid_ia = 31L)$root
}
gamma_uninf <- solve_gamma(uninf_ctrl) # -> 0.481
gamma_map <- solve_gamma(map_rate) # -> 0.691
## Calibrated assurance thresholds (targeting a 2% power loss under the
## alternative), from the one-off search above for the design inputs
## listed there. Note: the interim OC is integrated on a discrete
## Gauss-Hermite grid (Ngrid_ia = 31), so the achievable power loss is
## quantized in small steps and 2% is met only up to that granularity.
## These thresholds are the ones closest to a 2% loss (about 1.9% for
## the non-informative and about 2.1% for the MAP design); nudging gamma
## to the next grid step would jump the loss to ~2.6% / ~2.2%.
gamma_uninf <- 0.481
gamma_map <- 0.691With the thresholds fixed, we compare the two methods at their respective calibrated operating points: the power under the alternative (equal by construction, up to the ~2% loss and the quadrature granularity noted above) and the futility stopping probability under the null.
calib_scen <- c(`No benefit` = 0, `Design alt` = log_rr_design)
ct1 <- log_mu_ctrl + calib_scen
ct2 <- rep(log_mu_ctrl, length(calib_scen))
oc_cal_uninf <- make_oc_assurance(gamma_uninf, uninf_ctrl)(theta1 = ct1, theta2 = ct2)
oc_cal_map <- make_oc_assurance(gamma_map, map_rate)(theta1 = ct1, theta2 = ct2)
fixed_cal <- oc_fixed(ct1, ct2)| Scenario | Rate ratio | Power (no IA) | Power (no borrow) | Power (MAP) | Stop (no borrow) | Stop (MAP) |
|---|---|---|---|---|---|---|
| No benefit | 1.00 | 0.025 | 0.024 | 0.020 | 0.421 | 0.634 |
| Design alt | 0.65 | 0.800 | 0.781 | 0.778 | 0.051 | 0.054 |
Calibrated to the same (approximately 2%) power loss, the two methods differ clearly in their futility stopping under the null: the MAP design stops a truly ineffective drug substantially more often than the non-informative design (here about 63% versus 42%). In other words, for the same price in power, borrowing buys a markedly higher chance of correctly stopping a futile trial — the benefit the shared-threshold comparison understated.
Conditional and predictive power at interim
At an actual IA, two related quantities inform the go/no-go decision:
- Conditional power (CP): The probability of final success given a specific assumed true treatment effect. This is a frequentist concept — the unknown parameters are fixed.
- Predictive power / Probability of Success (PoS): The probability of final success integrating over parameter uncertainty. This is a Bayesian concept — the unknown parameters are drawn from the interim posterior.
These two quantities are closely linked rather than complementary: predictive power is essentially conditional power averaged over the interim posteriors. They answer different questions — “how likely is success if the effect is ?” versus “how likely is success accounting for our uncertainty about the effect?” — but they are not independent pieces of information.
Hypothesized interim state
We consider a scenario where at the IA (30% information fraction), the observed data suggest a moderate treatment effect:
## Observed interim summary statistics
ia_log_mu_ctrl <- 0.70 # placebo MLE on log-rate scale
ia_se_mu_ctrl <- sigma_fn(exp(0.70), kappa_true, followup) / sqrt(n_ctrl_ia)
ia_log_mu_treat <- 0.35 # treatment MLE (log RR ≈ -0.35)
ia_se_mu_treat <- sigma_fn(exp(0.35), kappa_true, followup) / sqrt(n_treat_ia)| Quantity | Value | SE |
|---|---|---|
| Interim log-rate control | 0.70 | 0.189 |
| Interim log-rate treatment | 0.35 | 0.198 |
| Observed log RR | -0.35 |
Conditional power
Conditional power evaluates the probability of final success
assuming the true treatment effect equals a specific value. We
construct this using oc2S with the interim posteriors as
“priors” for the remaining data:
## OC function conditioned on interim posteriors
cp_fn <- oc2S(post_treat_ia, post_ctrl_ia,
n1 = n_treat - n_treat_ia,
n2 = n_ctrl - n_ctrl_ia,
decision = success_crit,
family = nb_family,
offset1 = log_exposure, offset2 = log_exposure
)
## Evaluate across true log-rate ratios
log_rr_cp <- seq(0, -0.8, by = -0.025)
cp_values <- cp_fn(log_mu_ctrl + log_rr_cp,
rep(log_mu_ctrl, length(log_rr_cp)))
ggplot(data.frame(log_rr = log_rr_cp, cp = cp_values),
aes(exp(log_rr), cp)) +
geom_line(linewidth = 0.8) +
geom_hline(yintercept = c(0.5, 0.8),
linetype = "dashed", colour = "grey50") +
geom_vline(xintercept = exp(ia_log_mu_treat - ia_log_mu_ctrl),
linetype = "dotted", colour = "steelblue") +
annotate("text",
x = exp(ia_log_mu_treat - ia_log_mu_ctrl) * 1.05,
y = 0.95, label = "observed effect",
hjust = 0, size = 3, colour = "steelblue") +
labs(x = "Assumed true rate ratio",
y = "Conditional power",
title = "Conditional power at 30% IA") +
scale_x_log10()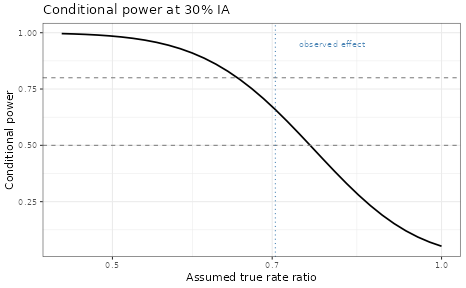
Conditional power at interim
Predictive power (Probability of Success)
Predictive power integrates over the interim posterior distribution of the treatment effect, providing a single summary that accounts for parameter uncertainty:
## PoS for remaining patients given interim posteriors
pos_fn <- pos2S(post_treat_ia, post_ctrl_ia,
n1 = n_treat - n_treat_ia,
n2 = n_ctrl - n_ctrl_ia,
decision = success_crit,
family = nb_family,
offset1 = log_exposure, offset2 = log_exposure
)
## Compute predictive power and conditional power at observed effect in one pass
pos_value <- pos_fn(post_treat_ia, post_ctrl_ia)
cp_at_obs <- cp_fn(ia_log_mu_treat, ia_log_mu_ctrl)| Metric | Value |
|---|---|
| Conditional power at observed effect | 0.738 |
| Predictive power (PoS) | 0.606 |
The predictive power is typically lower than the conditional power evaluated at the observed effect, because it accounts for the possibility that the true effect is smaller (or absent). As a result one would not usually use the same IA decision thresholds for conditional and predictive power.
Design-level power with futility IA
The individual-scenario analysis above is useful at the IA itself. At the design stage, we want to know the overall impact of the futility IA on power — averaging over all possible interim outcomes under an assumed truth.
For Normal-endpoint group-sequential Bayesian designs, the gsbDesign
package (Gerber & Gsponer, 2016) provides a full analytic treatment
of such operating characteristics via conjugate posterior updates. The
oc2S_interim() helper used here follows the same numerical
integration idea but works with the mixture-prior machinery in RBesT
(see Appendix: Integration
approach). We already computed these above. Calibrated to a common
2% power loss under the design alternative (rate ratio = 0.65), the MAP
prior achieves a higher futility stopping probability under the null
than the non-informative design — exactly the desired behaviour, and the
fair comparison the reviewer-facing literature calls for.
Discussion
This article demonstrated how historical information can be used only for an interim futility analysis:
- Establish the baseline without an IA.
- Quantify the cost of adding a futility IA with limited data.
- Show the benefit of a MAP prior, both in ESS/information fraction terms and in operating characteristics.
- Calibrate the decision threshold to a common power loss and compare methods on an equal footing, examining the behaviour across a range of decision thresholds via conditional and predictive power.
- Confirm at the design level that the power loss is acceptable via numerical integration.
Key insights:
- A futility IA at low information fractions (e.g. 30%) may be unreliable without supplementary information, because the uncertainty in the interim estimate is usually large.
- The MAP prior adds effective sample size to the control arm, boosting the information fraction at the IA and enabling sharper futility decisions.
- A useful way to read this benefit: borrowing lets us “look into the future.” The historical information sharpens the control arm to a precision the trial would otherwise only reach at a later, more mature interim look (here the information fraction rises from 30% to about 44%). Because the treatment effect contrasts treatment against control, a sharper control estimate directly tightens the interim effect estimate, so we make the futility call as if from a higher-information look. This is a partial look into the future: only the control arm is advanced — the treatment arm still carries its actual interim information — and it reaches only as far as the (robust) MAP stays consistent with the concurrent control; under prior-data conflict the borrowing is down-weighted and the effective gain shrinks. Crucially, this is an information gain.
- The final confirmatory analysis remains frequentist — no prior is imported. The MAP prior serves only as a decision supporting tool for interim analyses.
- Predictive power (PoS) is, in a certain sense, a more conservative and realistic interim metric than conditional power evaluated at the observed effect, because it integrates over parameter uncertainty instead of conditioning on a single assumed effect. It is not uniformly more conservative — it can exceed the conditional power at a pessimistic assumed effect — but it avoids the over-optimism of plugging in the observed interim estimate.
Using historical information on the negative binomial dispersion
parameter can be done using a normal-normal hierarchical model and then
used as a MAP prior at the IA. However, uncertainty about the
overdispersion parameter is not supported with RBesT
directly and would require using e.g. brms instead.
Limitations
- Overdispersion is treated as fixed. A more thorough analysis would derive a MAP prior for and integrate over its posterior uncertainty (cf. Holzhauer et al., 2018; see the companion article on SSR).
- The normal approximation on the log-rate scale assumes moderate to large event counts. For rare-event settings, exact likelihoods may be needed.
Acknowledgements
Many thanks to Björn Holzhauer for a thorough review of an earlier version of this article.
References
[1] Neuenschwander B. et al., Clin Trials. 2010;
7(1):5-18
[2] Holzhauer B., Wang C., Schmidli H. Evidence synthesis from aggregate
recurrent event data for clinical trial design and analysis.
Statistics in Medicine. 2018;37:867-882.
[3] Schmidli H. et al., Biometrics 2014;70(4):1023-1032
[4] Gerber F, Gsponer T (2016). “gsbDesign: An R Package for Evaluating
the Operating Characteristics of a Group Sequential Bayesian Design.”
Journal of Statistical Software, 69(11), 1–23.
doi: 10.18637/jss.v069.i11.
[5] Gsponer T, Gerber F, Bornkamp B, Ohlssen D, Vandemeulebroecke M,
Schmidli H (2014). “A Practical Guide to Bayesian Group Sequential
Designs.” Pharmaceutical Statistics, 13(1),
71–80. doi: 10.1002/pst.1593.
[6] Gallo P, Mao L, Shih VH (2014). “Alternative Views on Setting
Clinical Trial Futility Criteria.” Journal of Biopharmaceutical
Statistics, 24(5), 976–993. doi: 10.1080/10543406.2014.932285.
R Session Info
## R version 4.6.1 (2026-06-24)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] MASS_7.3-65 dplyr_1.2.1 ggplot2_4.0.3 knitr_1.51 RBesT_1.10-0
##
## loaded via a namespace (and not attached):
## [1] gtable_0.3.6 tensorA_0.36.2.1 xfun_0.59
## [4] bslib_0.11.0 QuickJSR_1.10.0 htmlwidgets_1.6.4
## [7] inline_0.3.21 vctrs_0.7.3 tools_4.6.1
## [10] generics_0.1.4 stats4_4.6.1 parallel_4.6.1
## [13] tibble_3.3.1 pkgconfig_2.0.3 checkmate_2.3.4
## [16] RColorBrewer_1.1-3 S7_0.2.2 desc_1.4.3
## [19] distributional_0.8.1 RcppParallel_5.1.11-2 assertthat_0.2.1
## [22] lifecycle_1.0.5 compiler_4.6.1 farver_2.1.2
## [25] stringr_1.6.0 textshaping_1.0.5 statmod_1.5.2
## [28] codetools_0.2-20 htmltools_0.5.9 sass_0.4.10
## [31] bayesplot_1.15.0 yaml_2.3.12 Formula_1.2-5
## [34] pillar_1.11.1 pkgdown_2.2.0 jquerylib_0.1.4
## [37] cachem_1.1.0 StanHeaders_2.32.10 abind_1.4-8
## [40] posterior_1.7.0 rstan_2.32.7 tidyselect_1.2.1
## [43] digest_0.6.39 mvtnorm_1.4-1 stringi_1.8.7
## [46] reshape2_1.4.5 labeling_0.4.3 fastmap_1.2.0
## [49] grid_4.6.1 cli_3.6.6 magrittr_2.0.5
## [52] loo_2.10.0 pkgbuild_1.4.8 withr_3.0.3
## [55] scales_1.4.0 backports_1.5.1 rmarkdown_2.31
## [58] matrixStats_1.5.0 otel_0.2.0 gridExtra_2.3.1
## [61] ragg_1.5.2 evaluate_1.0.5 rstantools_2.6.0
## [64] rlang_1.2.0 Rcpp_1.1.1-1.1 glue_1.8.1
## [67] jsonlite_2.0.0 plyr_1.8.9 R6_2.6.1
## [70] systemfonts_1.3.2 fs_2.1.0Exercise: calibrate to a fixed null-stopping probability
The calibration above fixed the power loss under the alternative at 2% and then compared the two methods on their futility stopping probability under the null. Because the futility scales are one-to-one for a fixed design (Gallo, Mao & Shih, 2014), we can equally read the trade-off the other way around: fix the probability of killing a truly ineffective drug under the null and compare the resulting power loss under the alternative. A sponsor who wants a guaranteed “kill rate” for futile trials would prefer this dual calibration.
As an exercise, calibrate both methods to a common futility stopping probability under the null — say 45% — and compare the power they sacrifice under the design alternative. You should find the MAP prior sacrifices less power for the same null-stopping guarantee, the mirror image of the result in the calibration section.
## Dual calibration: fix the futility stopping probability under the
## null (H0: no treatment benefit) instead of the power loss under the
## alternative. Reuses assurance_rule() / make_oc_assurance() from the
## calibration section.
target_stop_null <- 0.45
theta_null <- rep(log_mu_ctrl, 2) # control == treatment (RR = 1)
theta_alt <- c(log_mu_ctrl + log_rr_design, log_mu_ctrl)
## Solve for the assurance threshold giving the target null-stop rate,
## using the same two-stage (coarse -> refined) search as the
## calibration section: locate on the cheap Ngrid_ia = 11 grid, then
## refine on Ngrid_ia = 31 with a self-extending bracket. The null-stop
## probability increases with gamma, so extendInt = "upX" applies.
solve_gamma_null <- function(prior2_ia) {
gfun <- function(gamma, Ngrid_ia) {
s <- make_oc_assurance(gamma, prior2_ia, Ngrid_ia)(theta1 = theta_null[1],
theta2 = theta_null[2])["stop_prob"]
as.numeric(s) - target_stop_null
}
g_coarse <- uniroot(gfun, interval = c(0.05, 0.90), tol = 1e-3,
Ngrid_ia = 11L)$root
uniroot(gfun, interval = c(g_coarse - 0.01, g_coarse + 0.01),
extendInt = "upX", tol = 1e-3, Ngrid_ia = 31L)$root
}
g_uninf_null <- solve_gamma_null(uninf_ctrl)
g_map_null <- solve_gamma_null(map_rate)
## Power under the alternative at each calibrated threshold, versus the
## fixed-design power, gives the power loss to compare across methods.
power_fixed_alt <- oc_fixed(theta_alt[1], theta_alt[2])
loss_uninf <- power_fixed_alt -
make_oc_assurance(g_uninf_null, uninf_ctrl)(theta_alt[1], theta_alt[2])["power"]
loss_map <- power_fixed_alt -
make_oc_assurance(g_map_null, map_rate)(theta_alt[1], theta_alt[2])["power"]
## Expectation: loss_map < loss_uninf (MAP gives up less power for the
## same 45% chance of stopping a futile trial).Appendix: Integration approach for interim OC
Computing the operating characteristics of a design with an interim
analysis requires averaging over all possible interim outcomes. The
oc2S_interim() function (available via
system.file("extra", "oc2S_interim.R", package = "RBesT"))
does this via deterministic numerical integration
rather than Monte Carlo simulation, yielding smooth, noise-free OC
curves.
Decomposition
The unconditional power is
where are the interim summary statistics (MLEs on the log-rate scale) and are the true parameters.
The outer expectation is a 2D integral over the joint distribution of the interim summaries . Since the two arms are independent, this factors into a product of two 1D Normal integrals — handled by Gauss-Hermite quadrature.
Full-trial boundary reuse
The key performance insight is that the full-trial decision boundary can be computed once and reused at every quadrature point.
The final analysis decides based on the full-sample means , which are a deterministic function of the interim and remaining data:
Conditional on the interim data and the true parameter , the full-sample mean is Normal:
The decision boundary
— computed by decision2S_boundary() using the original
priors and full sample sizes — applies unchanged, because the sequential
Bayesian update property guarantees
At each quadrature point, the conditional OC reduces to
which is again evaluated by Gauss-Hermite quadrature (an inner 1D integral).
Appendix: Negative binomial parametrization
Distribution
For patient in arm with follow-up (exposure) time and mean event rate (events per unit time), the count follows
with probability mass function
and moments
Here is the overdispersion parameter. For the distribution reduces to Poisson. The treatment effect is parametrized as the rate ratio , or equivalently the log-rate ratio .
Parametrization conventions
Several conventions coexist in the literature:
| Convention | Overdispersion | Relation |
|---|---|---|
| (this article, Holzhauer et al.) | — | |
| (Mütze et al., rpact) | ||
theta in MASS::negative.binomial()
|
theta
|
theta
|
size in dnbinom()
|
size
|
size
|
Caution: R’s
MASS::negative.binomial(theta) uses theta as
the reciprocal of the overdispersion
(),
so larger values of theta mean less
overdispersion.
Fisher information on the log-rate scale
The analysis is conducted on the log mean rate scale, . The MLE is approximately normally distributed with variance (Fisher information inverse)
for patients each with exposure . The approximate Fisher information for arm is therefore
Key observations:
- Precision is event-driven: The numerator represents the expected total number of events. More events yield more information.
- Overdispersion is a tax: The denominator inflates the variance. Higher reduces the information per patient.
- Exposure matters: Longer follow-up increases the expected events and thus the information, but with diminishing returns when .
The variance of the log-rate ratio estimator is
Connecting to MASS::negative.binomial()
In RBesT’s design functions (oc1S, oc2S,
pos1S, pos2S), the family
argument accepts an object created by
MASS::negative.binomial(). This object encodes the
variance–mean relationship
,
which on the log-link scale translates exactly to the Fisher information
formula above.
## Create NB family with kappa = 1.9 (theta = 1/1.9)
kappa <- 1.9
nb <- MASS::negative.binomial(theta = 1 / kappa)
## The variance function: V(mu) = mu + mu^2 / theta = mu * (1 + kappa * mu)
mu_grid <- seq(0.5, 3, by = 0.5)
data.frame(
mu = mu_grid,
V_mu = nb$variance(mu_grid),
check = mu_grid * (1 + kappa * mu_grid)
)## mu V_mu check
## 1 0.5 0.975 0.975
## 2 1.0 2.900 2.900
## 3 1.5 5.775 5.775
## 4 2.0 9.600 9.600
## 5 2.5 14.375 14.375
## 6 3.0 20.100 20.100