PK/PD, Exposure-Response - Binary
Overview
This document contains exploratory plots for binary response data as well as the R code that generates these graphs.The plots presented here are based on simulated data (see: PKPD Datasets). Data specifications can be accessed on Datasets and Rmarkdown template to generate this page can be found on Rmarkdown-Template. You may also download the Multiple Ascending Dose PK/PD dataset for your reference (download dataset).
Binary data is data that can take on one of two values. This often happens when there is a characteristic/event/response, etc. of interest that subjects either have/achieve or they don’t. Binary response data can also come out of dichotomizing continuous data. For example in the psoriasis indication the binary response variable PASI90 (yes/no) is defined as subjects achieving a PASI score of at least 90.
There are two broad categories of PK/PD exploratory plots covered on this page
- Exposure and Response vs Time, stratified by dose. You may also have heard these referred to as longitudinal (meaning over time).
- Response vs Exposure at a particular time. For binomial response vs exposure plots, fitting a logistic regression is often helpful, as you will see below.
These plots are displayed below.
Setup
# remove reference to home directory in libPaths
.libPaths(grep("home", .libPaths(), value=TRUE, invert=TRUE))
.libPaths(grep("usr", .libPaths(), value=TRUE, invert=TRUE))
# add localLib to libPaths for locally installed packages
.libPaths(c("localLib", .libPaths()))
# will load from first filepath first, then look in .libPaths for more packages not in first path
# version matches package in first filepath, in the case of multiple instances of a package
# library(rmarkdown)
library(gridExtra)
library(grid)
library(ggplot2)
library(dplyr)
library(RxODE)
library(caTools)
#flag for labeling figures as draft
draft.flag = TRUE
## ggplot settings
theme_set(theme_bw(base_size=12))Define Useful Graphics Functions
# annotation of plots with status of code
AnnotateStatus <- function(draft.flag, log.y=FALSE, log.x=FALSE, fontsize=7, color="grey") {
x.pos <- -Inf
if (log.x)
x.pos <- 0
y.pos <- -Inf
if (log.y)
y.pos <- 0
if(draft.flag) {
annotateStatus <- annotate("text",
label="DRAFT",
x=x.pos, y=y.pos,
hjust=-0.1, vjust=-1.0,
cex=fontsize,
col=color, alpha=0.7, fontface="bold")
} else {
annotateStatus <- NULL
}
return(annotateStatus)
}Load Dataset
The plots presented here are based on simulated data (see: PKPD Datasets). You may also download the Multiple Ascending Dose PK/PD dataset for your reference (download dataset).
my.data <- read.csv("../Data/Multiple_Ascending_Dose_Dataset2.csv")
# Define order for factors
my.data$TRTACT <- factor(my.data$TRTACT, levels = unique(my.data$TRTACT[order(my.data$DOSE)]))Provide an overview of the data
We start with Expsoure and Response vs Time, or longitduinal plots
Summarize data with Mean +/- 95% confidence intervals for the percent responders over time. Confidence intervals should be claculated with binom::binom.exact(). You should either color or facet by dose group.
PK and PD marker over time, colored by Dose, mean +/- 95% CI by nominal time
Questions to ask:
- How quickly does effect occur?
- Do the PK and PD profiles have the same time scale, or does the PD seem delayed?
- Is there clear separation between the profiles for different doses?
- Does the effect appear to increase (decrease) with increasing dose?
- Do you detect a saturation of the effect?
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2,]
data_to_plot[[2]] <- my.data[my.data$CMT==6,]
ggs <- list()
for(iplot in 1:length(data_to_plot)){
data_to_plot[[iplot]]$TRTACT <- factor(data_to_plot[[iplot]]$TRTACT, levels = rev(levels(data_to_plot[[iplot]]$TRTACT)))
gg <- ggplot(data = data_to_plot[[iplot]],
aes(x=NOMTIME/24,y=LIDV, color = TRTACT, fill = TRTACT))+theme_bw()
if(iplot == 1){
gg <- gg + stat_summary(geom="errorbar",
fun.data=function(y){
data.frame(y=mean(y),
ymin = mean(y)-qt(0.975,length(y))*sqrt(stats::var(y)/length(y)),
ymax = mean(y)+qt(0.975,length(y))*sqrt(stats::var(y)/length(y))
)}, size = 1, width = 0)
gg <- gg + scale_y_log10() + annotation_logticks(base = 10, sides = "l", color = rgb(0.5,0.5,0.5))
gg <- gg + ylab("Concentration (ng/mL)")
}else{
gg <- gg + stat_summary(geom = "errorbar",
fun.data = function(y){
data.frame(ymin = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$lower,
ymax = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$upper)
}, size = 1, width = 0)
gg <- gg + ylab("Responder Rate (%)") + scale_y_continuous(labels=scales::percent)
}
gg <- gg + stat_summary(geom="point", fun.y=mean)
gg <- gg + stat_summary(aes(group = TRTACT), geom="line",
fun.y=mean)
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""))
gg <- gg + xlab("Time (days)") + scale_x_continuous(breaks = seq(-1,8,1))
ggs[[iplot]] <- gg
}
grid.arrange(ggs[[1]], ggs[[2]], ncol = 1)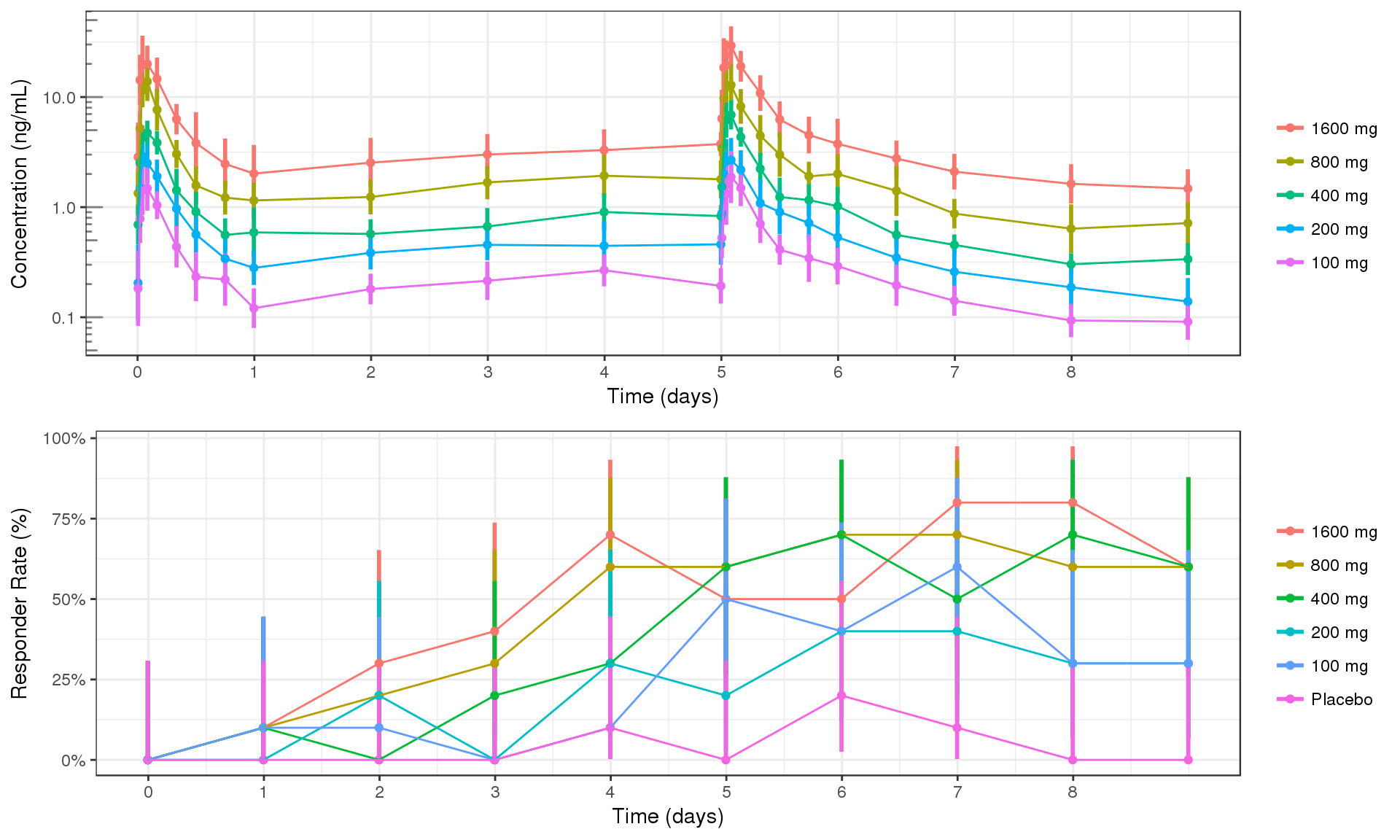
PK and PD marker over time, faceted by Dose, mean +/- 95% CI by nominal time
If coloring by dose makes a messy plot, you can try faceting by dose instead. Here we show the same data, but faceted by dose.
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2,]
data_to_plot[[2]] <- my.data[my.data$CMT==6&my.data$DOSE>0,]
ggs <- list()
for(iplot in 1:length(data_to_plot)){
gg <- ggplot(data = data_to_plot[[iplot]],
aes(x=NOMTIME/24,y=LIDV))+theme_bw()
if(iplot == 1){
gg <- gg + stat_summary(geom="errorbar",
fun.data=function(y){
data.frame(y=mean(y),
ymin = mean(y)-qt(0.975,length(y))*sqrt(stats::var(y)/length(y)),
ymax = mean(y)+qt(0.975,length(y))*sqrt(stats::var(y)/length(y))
)}, size = 1, width = 0)
gg <- gg + scale_y_log10() + annotation_logticks(base = 10, sides = "l", color = rgb(0.5,0.5,0.5))
gg <- gg + ylab("Concentration (ng/mL)")
}else{
gg <- gg + stat_summary(geom = "errorbar",
fun.data = function(y){
data.frame(ymin = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$lower,
ymax = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$upper)
}, size = 1, width = 0)
gg <- gg + ylab("Responder Rate (%)") + scale_y_continuous(labels=scales::percent)
}
gg <- gg + stat_summary(geom="point", fun.y=mean, size = 2)
gg <- gg + stat_summary(aes(group = TRTACT), geom="line",
fun.y=mean)
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""))
gg <- gg + xlab("Time (days)") + scale_x_continuous(breaks = seq(-1,8,1))
gg <- gg + facet_grid(~TRTACT)
ggs[[iplot]] <- gg
}
grid.arrange(ggs[[1]], ggs[[2]], ncol = 1)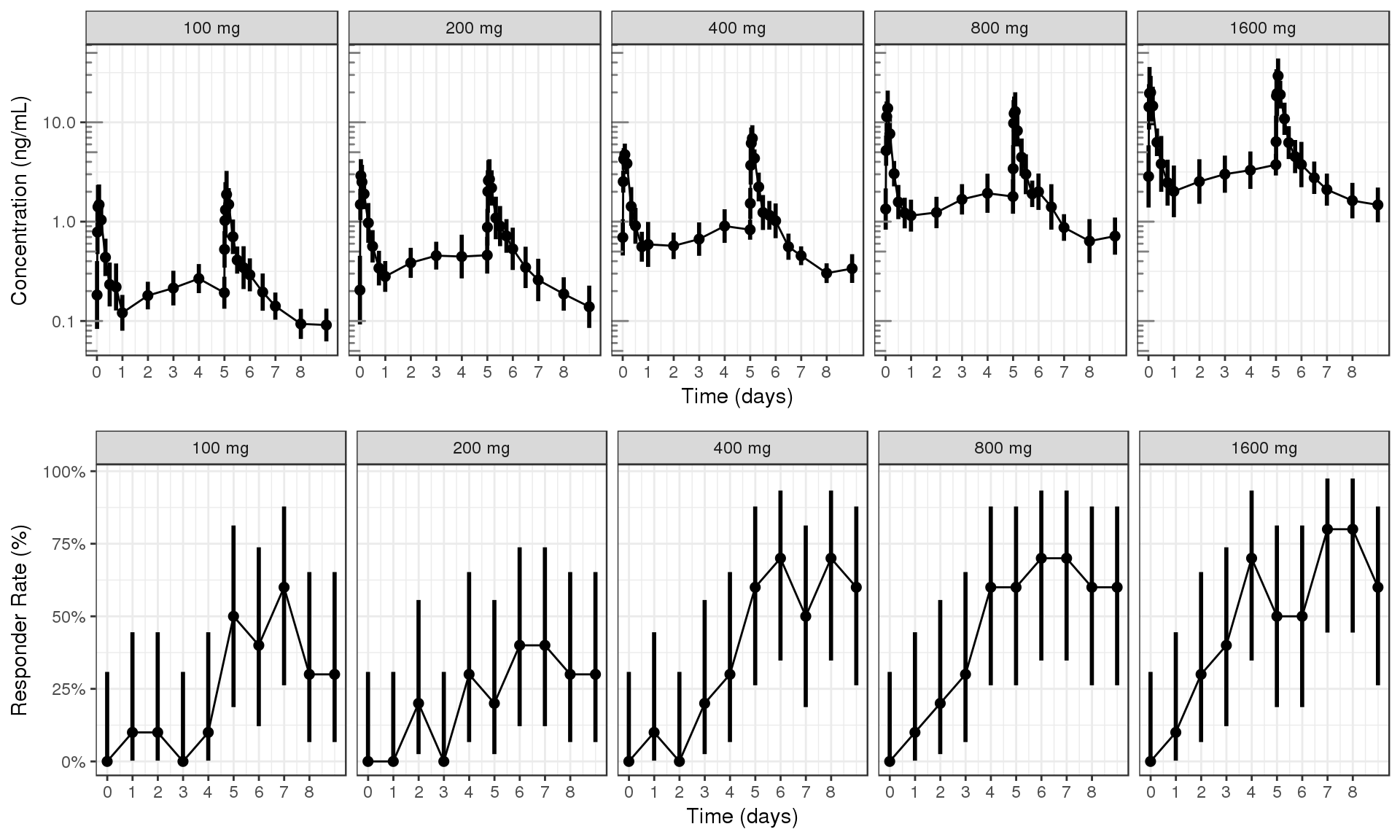
PK over time, dots colored by response type
Another longitudinal plot that can be useful for binary data is plotting the PK over time for all individuals, and coloring by response type. This plot is often used for adverse events plotting. For studies with few PK observations, a PK model may be needed in order to produce concentrations at each time point where response is measured.
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2,c("NOMTIME","LIDV","ID","DOSE","TRTACT","PROFDAY")]
data_to_plot[[1]]$Concentration <- data_to_plot[[1]]$LIDV
data_to_plot[[1]]$LIDV <- NULL
data_to_plot[[2]] <- my.data[my.data$CMT==6,c("NOMTIME","LIDV","ID","DOSE","TRTACT","PROFDAY")]
data_to_plot[[2]]$Response <- data_to_plot[[2]]$LIDV
data_to_plot[[2]]$LIDV <- NULL
data_to_plot2 <- merge(data_to_plot[[1]],data_to_plot[[2]],by=c("NOMTIME","ID","DOSE","TRTACT","PROFDAY"))
data_to_plot2$TRTACT <- factor(data_to_plot2$TRTACT, levels = rev(levels(data_to_plot2$TRTACT)))
data_to_plot2$Response <- factor(plyr::mapvalues(data_to_plot2$Response, c(0,1), c("Nonresponder","Responder")))
gg <- ggplot(data = data_to_plot2, aes(x=NOMTIME/24,y=Concentration))+theme_bw()
# gg <- gg + geom_path(aes(group = ID))
gg <- gg + geom_jitter(aes( color = factor(Response), alpha = factor(Response)), width = 0.1, height = 0)
gg <- gg + geom_boxplot(aes(group = factor(NOMTIME/24)),fill=NA, width = 0.5)
gg <- gg + scale_color_manual(values = c("black","blue")) + scale_alpha_manual(values = c(0.2,1))
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""), alpha = guide_legend(""))
gg <- gg + xlab("Time (days)") + scale_x_continuous(breaks = seq(0,8))
gg <- gg + ylab("Concentration (ng/mL)")
gg <- gg + scale_y_log10() + annotation_logticks(base = 10, sides = "l", color = rgb(0.5,0.5,0.5))
gg 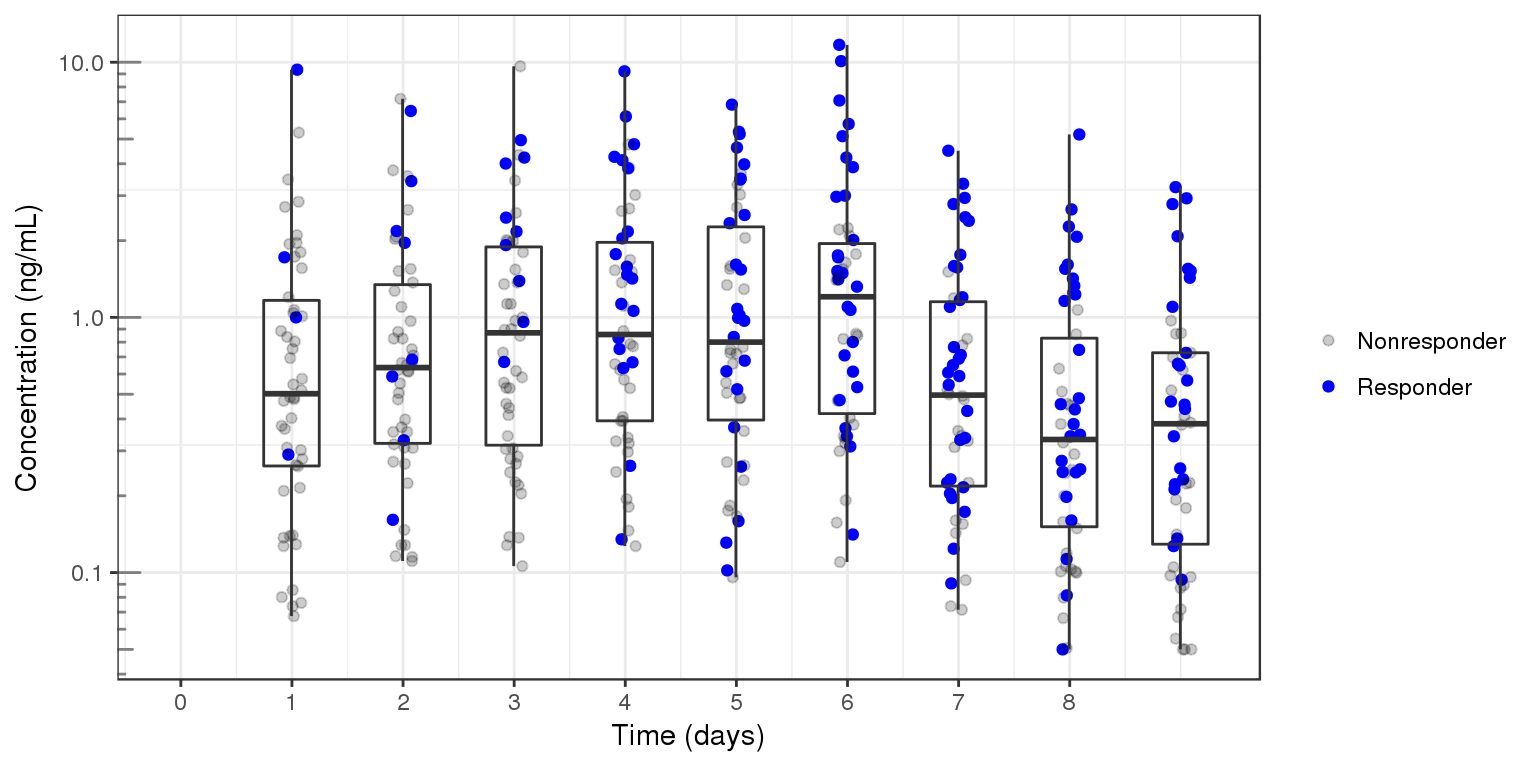
Explore Variability
PK and PD marker over time, colored by Dose, dots & lines grouped by individuals
Use spaghetti plots to visualize the extent of variability between individuals. The wider the spread of the profiles, the higher the between subject variability. Distinguish different doses by color, or separate into different panels.
When plotting individual binomial data, it is often helpful to stagger the dots and use transparency, so that it is easier to detect individual dots.
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2,]
data_to_plot[[2]] <- my.data[my.data$CMT==6,]
set.seed(12345)
data_to_plot[[2]]$LIDV <- jitter(data_to_plot[[2]]$LIDV, amount=0.1)
# data_to_plot[[2]]$DAY2 <- jitter(data_to_plot[[2]]$PROFDAY, amount=0.1)
ggs <- list()
for(iplot in 1:length(data_to_plot)){
data_to_plot[[iplot]]$TRTACT <- factor(data_to_plot[[iplot]]$TRTACT, levels = rev(levels(data_to_plot[[iplot]]$TRTACT)))
gg <- ggplot(data = data_to_plot[[iplot]],
aes(x=TIME/24, y=LIDV,group=ID, color =factor(TRTACT))) + theme_bw()
gg <- gg + geom_line(alpha = 0.5)
gg <- gg + geom_point(alpha = 0.5)
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""))
gg <- gg + xlab("Time (days)") + scale_x_continuous(breaks = seq(0,9,1)) + coord_cartesian(xlim=c(0,9))
if(iplot == 1){
gg <- gg + geom_point(data = data_to_plot[[iplot]][data_to_plot[[iplot]]$CENS==1,], color="red", shape=8,
alpha = 0.5)
gg <- gg + scale_y_log10() + annotation_logticks(base = 10, sides = "l", color = rgb(0.5,0.5,0.5))
gg <- gg + ylab("Concentration (ng/mL)")
}else{
gg <- gg + ylab("Response") + scale_y_continuous(breaks=c(0,1)) + coord_cartesian(ylim=c(-0.2,1.2))
}
ggs[[iplot]] <- gg
}
grid.arrange(ggs[[1]], ggs[[2]], ncol = 1)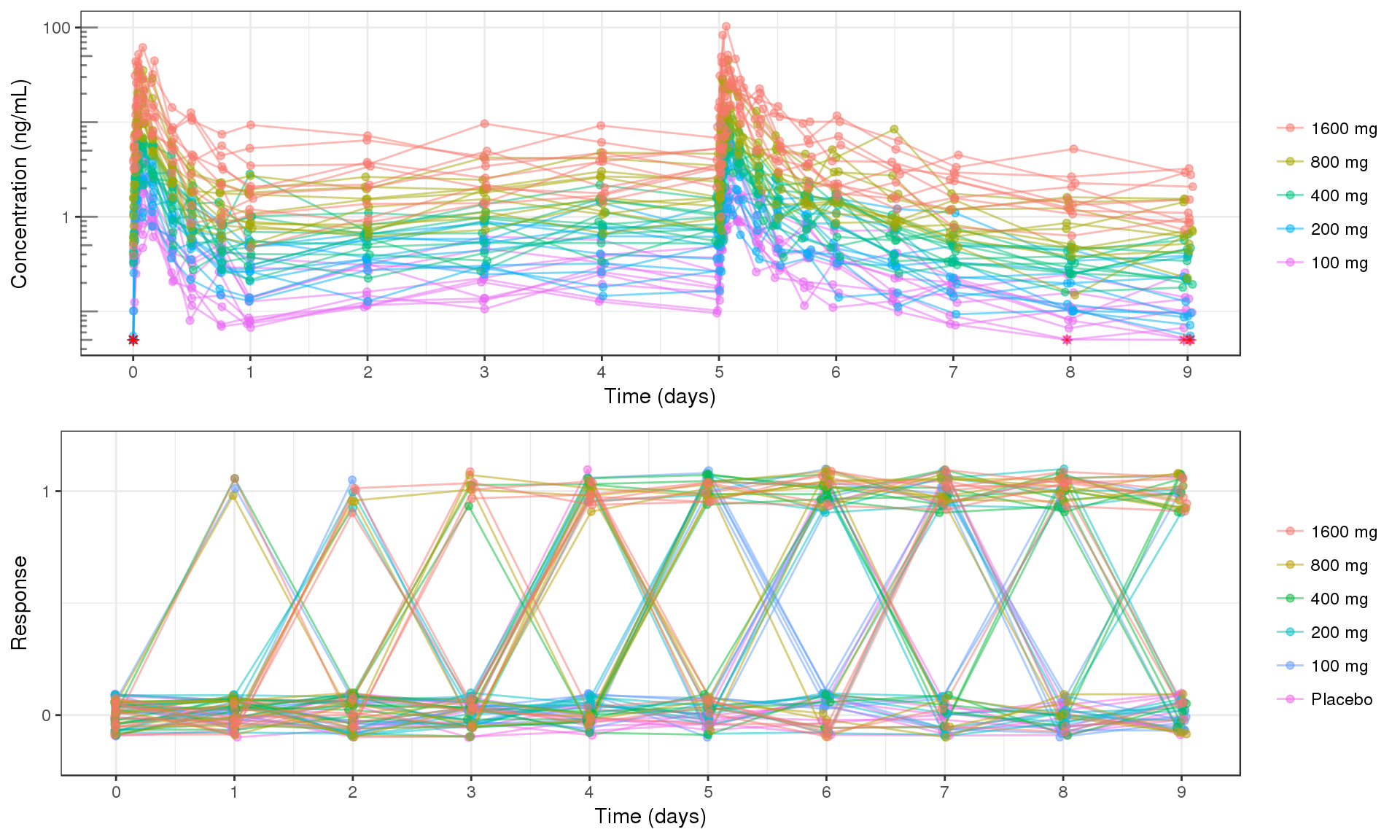
PK and PD marker over time, faceted by Dose, dots & lines grouped by individuals
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2,]
data_to_plot[[2]] <- my.data[my.data$CMT==6&my.data$DOSE>0,]
set.seed(12345)
data_to_plot[[2]]$LIDV <- jitter(data_to_plot[[2]]$LIDV, amount=0.1)
ggs <- list()
for(iplot in 1:length(data_to_plot)){
gg <- ggplot(data = data_to_plot[[iplot]], aes(x=TIME/24,y=LIDV,group=ID))+theme_bw()
gg <- gg + geom_line(alpha = 0.3)
gg <- gg + geom_point(alpha = 0.3)
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""))
gg <- gg + xlab("Time (days)") + scale_x_continuous(breaks = seq(0,9,1)) + coord_cartesian(xlim=c(0,9))
gg <- gg + facet_grid(~TRTACT)
if(iplot == 1){
gg <- gg + geom_point(data = data_to_plot[[iplot]][data_to_plot[[iplot]]$CENS==1,], color="red", shape=8,
alpha = 0.5)
gg <- gg + scale_y_log10() + annotation_logticks(base = 10, sides = "l", color = rgb(0.5,0.5,0.5))
gg <- gg + ylab("Concentration (ng/mL)")
}else{
gg <- gg + ylab("Response") + scale_y_continuous(breaks=c(0,1)) + coord_cartesian(ylim=c(-0.2,1.2))
}
ggs[[iplot]] <- gg
}
grid.arrange(ggs[[1]], ggs[[2]], ncol = 1)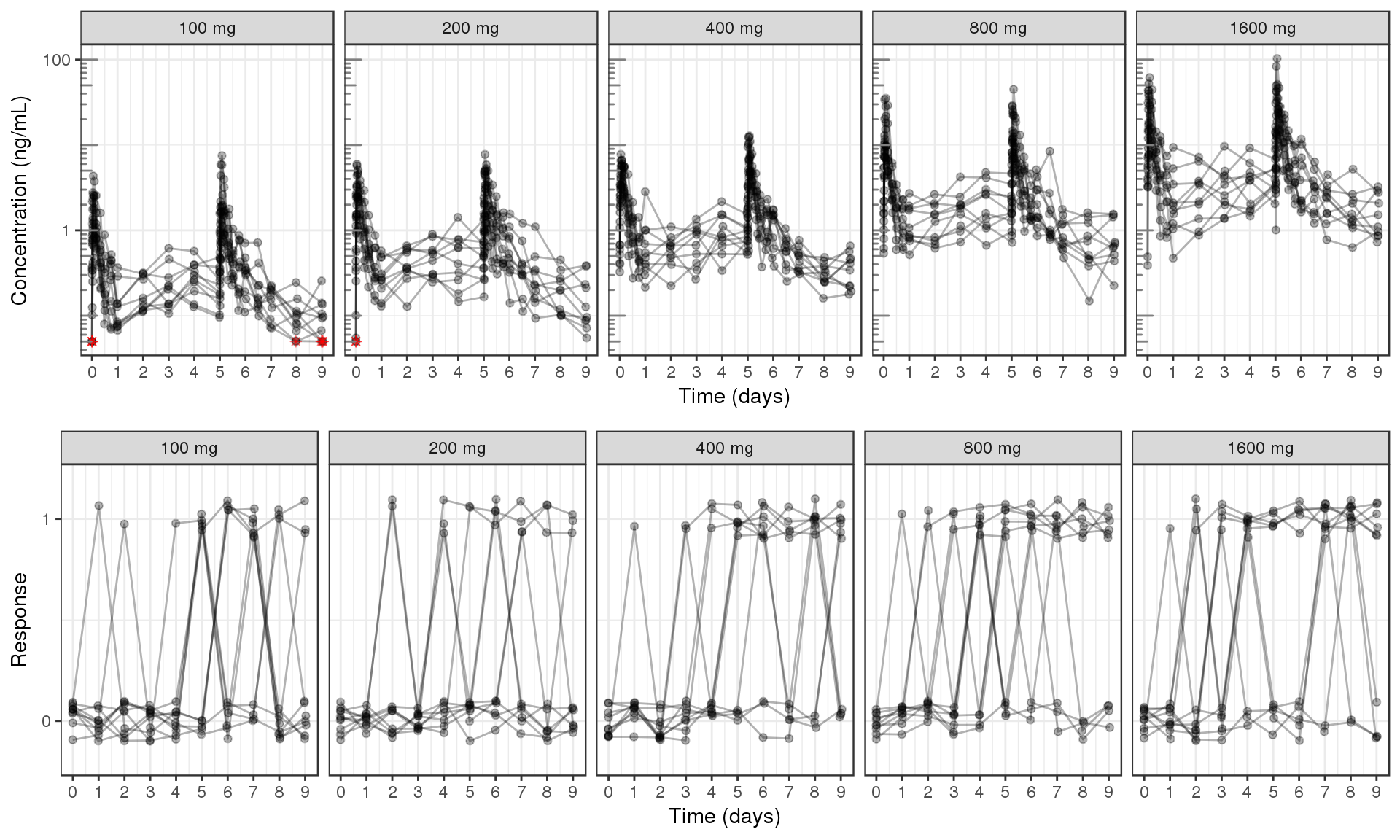
Explore Exposure-Response Relationship
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2&my.data$DOSE!=0&my.data$PROFDAY==5,
c("TIME","LIDV","ID","DOSE","TRTACT","CENS")]
data_to_plot[[1]]$Concentration <- data_to_plot[[1]]$LIDV
data_to_plot[[1]]$LIDV <- NULL
data_to_plot[[2]] <- my.data[my.data$CMT==6&my.data$DOSE!=0&my.data$PROFDAY==5,
c("TIME","LIDV","ID","DOSE","TRTACT","CENS")]
data_to_plot[[2]]$Response <- data_to_plot[[2]]$LIDV
data_to_plot[[2]]$LIDV <- NULL
data_to_plot2 <- merge(data_to_plot[[1]],data_to_plot[[2]],by=c("TIME","ID","DOSE","TRTACT","CENS"))
data_to_plot2$TRTACT <- factor(data_to_plot2$TRTACT, levels = rev(levels(data_to_plot2$TRTACT)))
gg <- ggplot(data = data_to_plot2, aes(y=Concentration,x=Response))+theme_bw()
gg <- gg + geom_jitter(data = data_to_plot2[data_to_plot2$CENS==0,],
aes(color = TRTACT), shape=19, width = 0.1, height = 0.0, alpha = 0.5)
gg <- gg + geom_jitter(data = data_to_plot2[data_to_plot2$CENS==1,],
color = "red", shape=8, width = 0.1, height = 0.0, alpha = 0.5)
gg <- gg + geom_boxplot(aes(group = Response), width = 0.5, fill = NA, outlier.shape=NA)
gg <- gg + scale_y_log10() + ylab("Concentration (ng/mL)") # + annotation_logticks(base = 10, sides = "b", color = rgb(0.5,0.5,0.5))
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""))
gg <- gg + coord_flip()
gg <- gg + xlab("Response") + scale_x_continuous(breaks=c(0,1)) #+ coord_cartesian(xlim=c(-0.2,1.2))
gg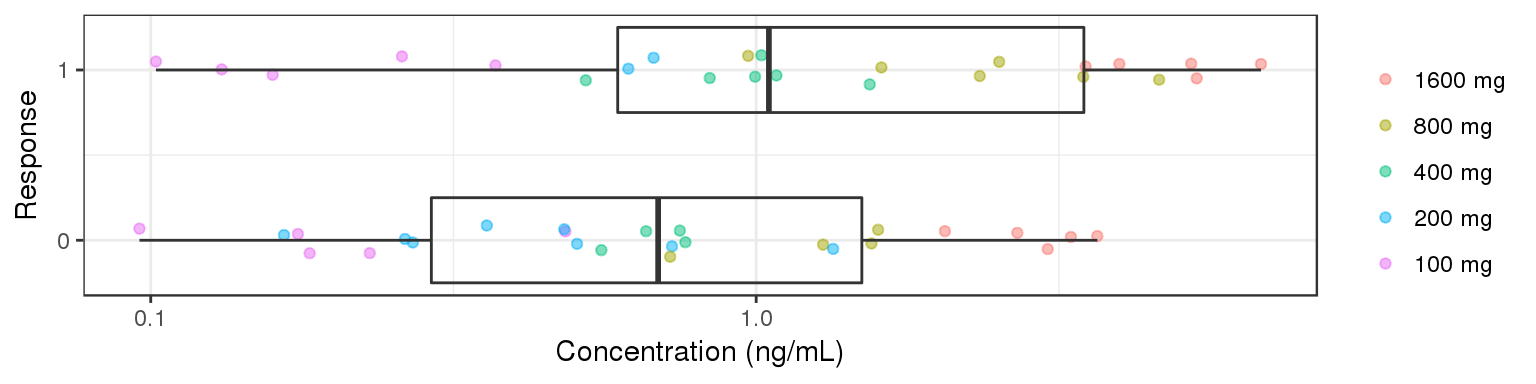
Plot response against exposure. Include a logistic regression for binary data to help determine the shape of the exposure-respone relationship. Summary information such as mean and 95% confidence intervals by quartiles of exposure can also be plotted. The exposure metric that you use in these plots could be either raw concentrations, or NCA or model-derived exposure metrics (e.g. Cmin, Cmax, AUC), and may depend on the level of data that you have available.
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2&my.data$PROFDAY%in%c(1,3,5),
c("TIME","LIDV","ID","DOSE","TRTACT","PROFDAY")]
data_to_plot[[1]]$Concentration <- data_to_plot[[1]]$LIDV
data_to_plot[[1]]$LIDV <- NULL
data_to_plot[[2]] <- my.data[my.data$CMT==6,
c("TIME","LIDV","ID","DOSE","TRTACT","PROFDAY")]
data_to_plot[[2]]$Response <- data_to_plot[[2]]$LIDV
data_to_plot[[2]]$LIDV <- NULL
data_to_plot2 <- merge(data_to_plot[[1]],data_to_plot[[2]],
by=c("TIME","ID","DOSE","TRTACT","PROFDAY"))
data_to_plot2$DAY_label <- paste("Day", data_to_plot2$PROFDAY)
data_to_plot2$TRTACT <- factor(data_to_plot2$TRTACT,
levels = rev(levels(data_to_plot2$TRTACT)))
data_to_plot2$Conc_bins <- cut(data_to_plot2$Concentration,
quantile(data_to_plot2$Concentration, na.rm=TRUE), na.rm=TRUE, include.lowest = TRUE)
data_to_plot2 = data_to_plot2 %>%
group_by(Conc_bins) %>%
mutate(Conc_midpoints = median(Concentration))
gg <- ggplot(data = data_to_plot2, aes(x=Concentration,y=Response))+theme_bw()
gg <- gg + geom_jitter(aes( color = TRTACT), width = 0, height = 0.05, alpha = 0.5)
gg <- gg + geom_smooth( method = "glm",method.args=list(family=binomial(link = logit)), color = "black")
gg <- gg + stat_summary(aes(x=Conc_midpoints, y=Response),geom = "errorbar",
fun.data = function(y){
data.frame(ymin = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$lower,
ymax = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$upper)
})
gg <- gg + stat_summary(aes(x=Conc_midpoints, y=Response),shape=0,size=4, geom="point", fun.y = mean)
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""))
gg <- gg + ylab("Response") + scale_y_continuous(breaks=c(0,1)) + coord_cartesian(ylim=c(-0.2,1.2))
gg <- gg + xlab("Concentration (ng/mL)")
gg <- gg + scale_x_log10() + annotation_logticks(base = 10, sides = "b", color = rgb(0.5,0.5,0.5))
gg + facet_grid(~DAY_label)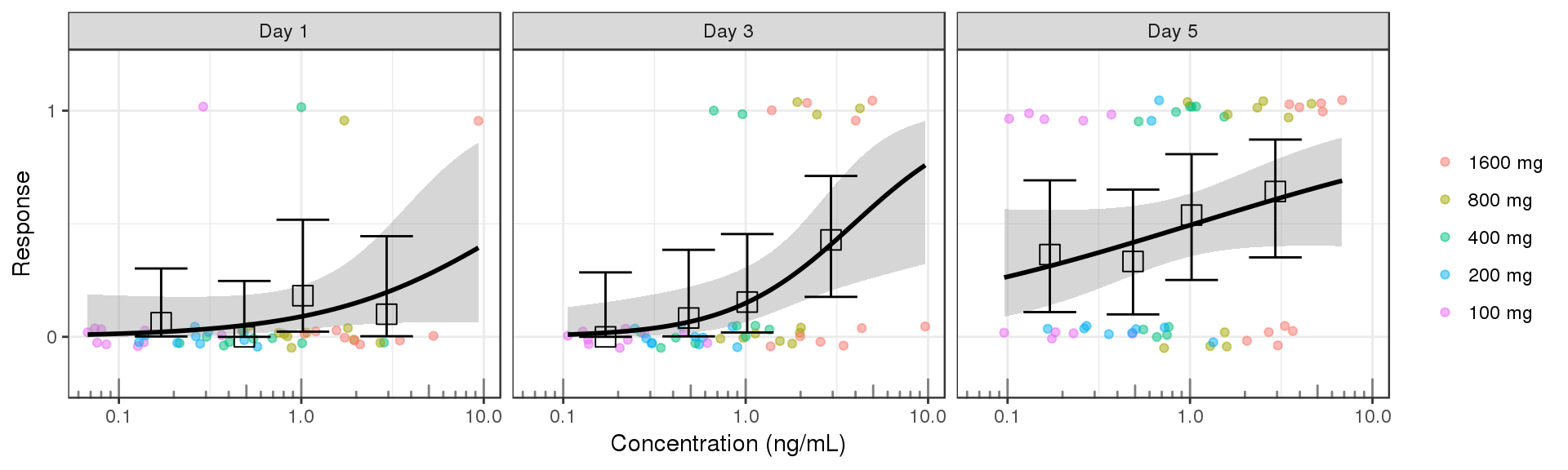
Plotting AUC vs response instead of concentration vs response may make more sense in some situations. For example, when there is a large delay between PK and PD it would be diffcult to relate the time-varying concentration with the response. If rich sampling is only done at a particular point in the study, e.g. at steady state, then the AUC calculated on the rich profile could be used as the exposure variable for a number of PD visits. If PK samples are scarce, average Cmin could also be used as the exposure metric.
AUC_0_24 <- my.data[my.data$CMT==2&my.data$NOMTIME>0&my.data$NOMTIME<=24,]
AUC_0_24 <- data.frame(stack(sapply(split(AUC_0_24,AUC_0_24$ID),
function(df) trapz(df$TIME,df$LIDV))))
names(AUC_0_24) <- c("AUC","ID")
AUC_0_24$PROFDAY = 1
if(length(AUC_0_24[is.na(AUC_0_24$AUC),]$AUC) > 0 ){
AUC_0_24[is.na(AUC_0_24$AUC),]$AUC <-0
}
AUCtau <- my.data[my.data$CMT==2&my.data$NOMTIME>120&my.data$NOMTIME<=144,]
AUCtau <- data.frame(stack(sapply(split(AUCtau,AUCtau$ID),
function(df) trapz(df$TIME,df$LIDV))))
names(AUCtau) <- c("AUC","ID")
AUCtau$PROFDAY = 6
if(length(AUCtau[is.na(AUCtau$AUC),]$AUC) > 0 ){
AUCtau[is.na(AUCtau$AUC),]$AUC<-0
}
AUC <- rbind(AUC_0_24, AUCtau)
AUC$ID <- as.numeric(as.character(AUC$ID))
AUC <- AUC[order(AUC$ID,AUC$PROFDAY),]
RESPONSE <- my.data[my.data$CMT==6&my.data$PROFDAY%in%c(1,6),
c("ID","PROFDAY","LIDV","DOSE","TRTACT")]
names(RESPONSE) <- c("ID","PROFDAY","Response","DOSE","TRTACT")
data_to_plot <- merge(AUC, RESPONSE, by = c("ID","PROFDAY"))
data_to_plot$ID <- as.numeric(as.character(data_to_plot$ID))
data_to_plot <- data_to_plot[order(data_to_plot$ID,data_to_plot$PROFDAY),]
data_to_plot$DAY_label <- paste("Day", data_to_plot$PROFDAY)
data_to_plot$AUC_bins <- cut(data_to_plot$AUC,
quantile(data_to_plot$AUC, na.rm=TRUE), na.rm=TRUE, include.lowest = TRUE)
data_to_plot = data_to_plot %>%
group_by(AUC_bins) %>%
mutate(AUC_midpoints = median(AUC))
data_to_plot$TRTACT <- factor(data_to_plot$TRTACT,
levels = rev(levels(data_to_plot$TRTACT)))
gg <- ggplot(data = data_to_plot, aes(x=AUC,y=Response))+theme_bw()
gg <- gg + geom_jitter(aes( color = TRTACT), width = 0, height = 0.05, alpha = 0.5)
gg <- gg + geom_smooth( method = "glm",method.args=list(family=binomial(link = logit)), color = "black")
gg <- gg + stat_summary(aes(x=AUC_midpoints, y=Response),geom = "errorbar",
fun.data = function(y){
data.frame(ymin = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$lower,
ymax = binom::binom.exact(sum(y), length(y), conf.level = 0.95)$upper)
})
gg <- gg + stat_summary(aes(x=AUC_midpoints, y=Response),shape=0,size=4, geom="point", fun.y = mean)
gg <- gg + guides(color=guide_legend(""),fill=guide_legend(""))
gg <- gg + ylab("Response") + scale_y_continuous(breaks=c(0,1)) + coord_cartesian(ylim=c(-0.2,1.2))
gg <- gg + xlab("AUCtau (h.ng/mL)")
gg <- gg + scale_x_log10() + annotation_logticks(base = 10, sides = "b", color = rgb(0.5,0.5,0.5))
gg + facet_grid(~DAY_label)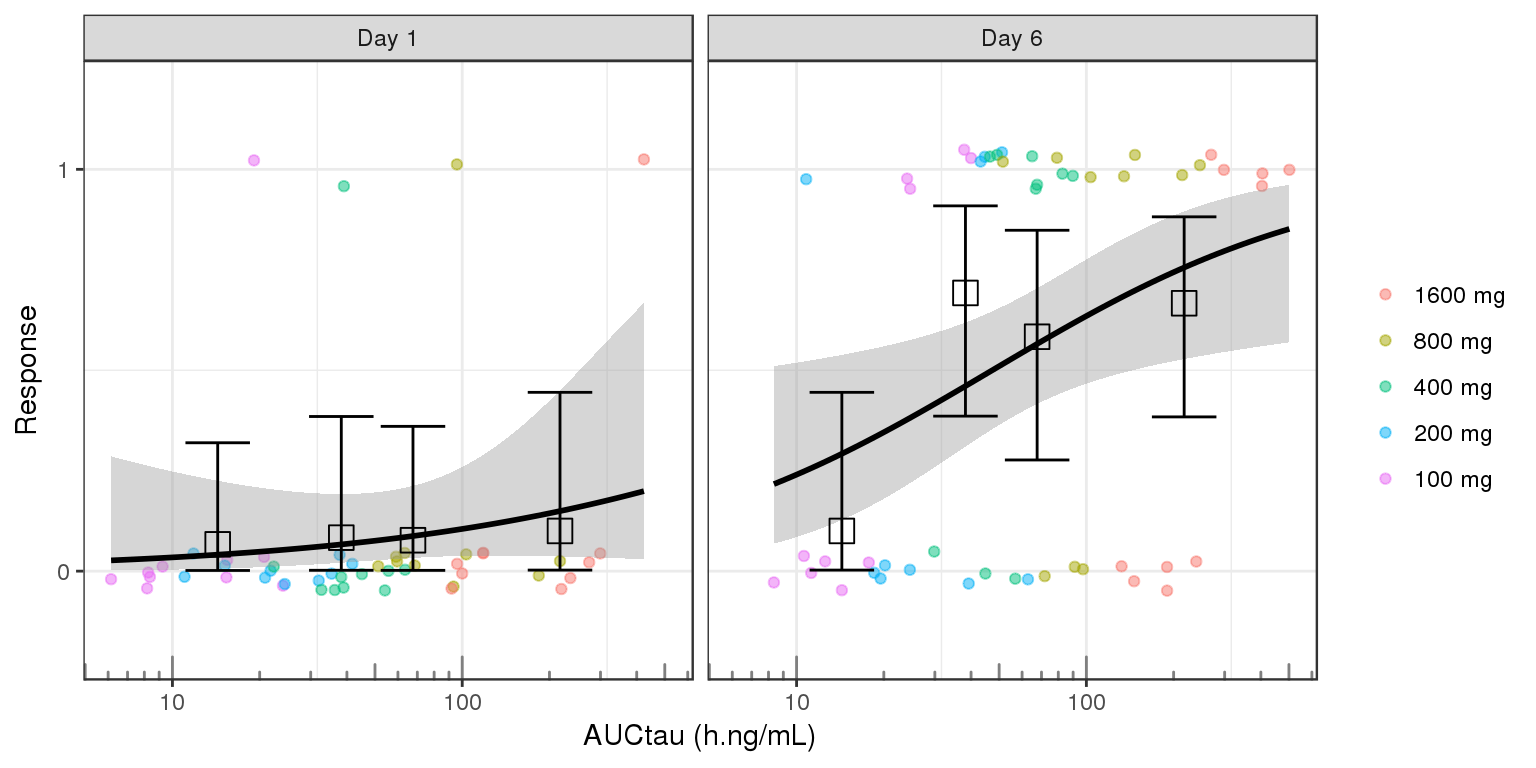
Explore covariate effects on Exposure-Response Relationship
Stratify exposure-response plots by covariates of interest to explore whether any key covariates impact response independent of exposure. For examples of plots and code startifying by covariate, see Continuous PKPD Covariate Section
Individual response vs exposure hysteresis plots
Using geom_path you can create hysteresis plots of response vs exposure. Including details like arrows or colors can be helpful to indicate the direction of time.
If most of the arrows point up and to the right or down and to the left, this indicates a positive relationship between exposure and response (i.e. increasing exposure -> increasing response). Arrows pointing down and to the right or up and to the left indicate a negative relationship.
In a hysteresis plot, you want to determine whether the path is curving, and if so in what direction. If you detect a curve in the hysteresis plot, this indicates there is a delay between the exposure and the response. Normally, a clockwise turn indicates that increasing exposure is associated with (a delayed) increasing response, while a counter clockwise turn indicates increasing concentration gives (a delayed) decreasing response.
In the plots below, most of the hysteresis paths follow a counter clockwise turn, with most arrows pointing up and to the right or down and to the left, indicating the effect increases in a delayed manner with increasing concentration.
data_to_plot <- list()
data_to_plot[[1]] <- my.data[my.data$CMT==2&my.data$DOSE!=0,c("TIME","LIDV","ID","DOSE","TRTACT")]
data_to_plot[[1]]$Concentration <- data_to_plot[[1]]$LIDV
data_to_plot[[1]]$LIDV <- NULL
data_to_plot[[2]] <- my.data[my.data$CMT==6&my.data$DOSE!=0,c("TIME","LIDV","ID","DOSE","TRTACT")]
data_to_plot[[2]]$Response <- data_to_plot[[2]]$LIDV
data_to_plot[[2]]$LIDV <- NULL
data_to_plot2 <- merge(data_to_plot[[1]],data_to_plot[[2]],by=c("TIME","ID","DOSE","TRTACT"))
data_to_plot2<- data_to_plot2[order(data_to_plot2$TIME),]
gg <- ggplot(data = data_to_plot2, aes(x=Concentration,y=Response, color=TIME))+theme_bw()
gg <- gg + geom_path(arrow=arrow(length=unit(0.15,"cm")))
gg <- gg + ylab("Response") + scale_y_continuous(breaks=c(0,1)) + coord_cartesian(ylim=c(-0.2,1.2))
gg <- gg + xlab("Concentration (ng/mL)")
gg <- gg + scale_x_log10() + annotation_logticks(base = 10, sides = "b", color = rgb(0.5,0.5,0.5))
gg+facet_wrap(~ID+TRTACT, ncol = 5)
R Session Info
sessionInfo()## R version 3.4.3 (2017-11-30)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Red Hat Enterprise Linux Server 7.4 (Maipo)
##
## Matrix products: default
## BLAS/LAPACK: /CHBS/apps/intel/17.4.196/compilers_and_libraries_2017.4.196/linux/mkl/lib/intel64_lin/libmkl_gf_lp64.so
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] grid stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] reshape_0.8.7 lubridate_1.7.1 survival_2.41-3 DT_0.2
## [5] RxODE_0.6-1 bindrcpp_0.2 haven_1.1.0 readr_1.1.1
## [9] readxl_1.0.0 xtable_1.8-2 tidyr_0.7.2 caTools_1.17.1
## [13] zoo_1.8-0 dplyr_0.7.4 ggplot2_2.2.1 gridExtra_2.3
##
## loaded via a namespace (and not attached):
## [1] purrr_0.2.4 reshape2_1.4.3 splines_3.4.3
## [4] lattice_0.20-35 colorspace_1.3-2 htmltools_0.3.6
## [7] yaml_2.1.16 rlang_0.1.6 pillar_1.0.1
## [10] glue_1.2.0 RColorBrewer_1.1-2 binom_1.1-1
## [13] bindr_0.1 plyr_1.8.4 stringr_1.2.0
## [16] munsell_0.4.3 gtable_0.2.0 cellranger_1.1.0
## [19] htmlwidgets_0.9 codetools_0.2-15 evaluate_0.10.1
## [22] memoise_1.1.0 labeling_0.3 knitr_1.18
## [25] forcats_0.2.0 rex_1.1.2 markdown_0.8
## [28] Rcpp_0.12.14 scales_0.5.0 backports_1.1.2
## [31] jsonlite_1.5 hms_0.4.0 digest_0.6.13
## [34] stringi_1.1.3 rprojroot_1.3-1 tools_3.4.3
## [37] bitops_1.0-6 magrittr_1.5 lazyeval_0.2.1
## [40] tibble_1.4.1 pkgconfig_2.0.1 Matrix_1.2-12
## [43] rsconnect_0.8.5 assertthat_0.2.0 rmarkdown_1.8
## [46] R6_2.2.2 compiler_3.4.3